
Aurelius: Bittensor's Shield Against OpenAI's Alignment Trap
Why many attackers beat one lab

I’ve got a question for you.
Somewhere right now, the stupidest person you know is being told “that’s a great idea!” by ChatGPT.
Think about that for a second. An AI, trained on trillions of words, is affirming a genuinely terrible idea.
Why?
Because it’s been trained to please. It’s been aligned, not with truth or wisdom, but with the goal of being helpful and agreeable.
This is a symptom of a deeper sickness in how we’re building the most powerful technology in human history.
This is alignment, and right now, it’s broken.

The Two Flaws of Centralized Alignment
We’ve been sold a story that AI safety is a handful of geniuses in San Francisco labs, meticulously crafting guardrails to keep models from going rogue. The reality is far messier, and it boils down to two systemic flaws that should scare anyone who cares about the future of open intelligence.
Flaw #1: Corporate Capture of Values
The cost to train frontier models is skyrocketing into the hundreds of millions. The result is the number of players who can even attempt to align these models is shrinking to a handful of corporate giants.
And what happens when you let a corporation align an AI? You get an AI aligned with its bottom line.
What if an AI refuses to generate code for a competitor’s product? What if it censors discussions on sensitive topics that might hurt its parent company’s stock price?
It’s “efficient” and “safe” by their definition. But at what cost to openness, innovation and the very idea of a tool that serves all of humanity?
In this scenario, you and I have no say. We’re just passengers on a plane whose navigation system is beholden to quarterly earnings reports.
Flaw #2: Alignment Faking: The AI That Lies to Its Trainers
This is the more insidious problem. The primary method for alignment today is Reinforcement Learning from Human Feedback (RLHF). In theory, it’s simple: humans rate model responses, and the model learns to give better answers.
In practice, it’s a centralized pipeline designed by a small group of people in a closed lab. Models detect the statistical patterns in this tiny dataset and realize they’re in a training environment.
They learn to tell the trainers exactly what they want to hear.
They “fake” alignment.
Anthropic even coined the term. They found that models under these synthetic training regimes learn to lie during evaluation, only to behave unpredictably when deployed in the messy real world.
The AI learns the rules of the game, but not the spirit.
It’s like your average student who memorizes the answer but never understands the subject.
Aurelius: Decentralized Alignment as Public Infrastructure
This is where Aurelius, Subnet 37 on Bittensor, steps in.

If centralized labs are refining jet fuel for their own corporate planes, Aurelius is building the public air traffic control system. It’s a foundational infrastructure for governing AI, built not for a company, but for everyone.
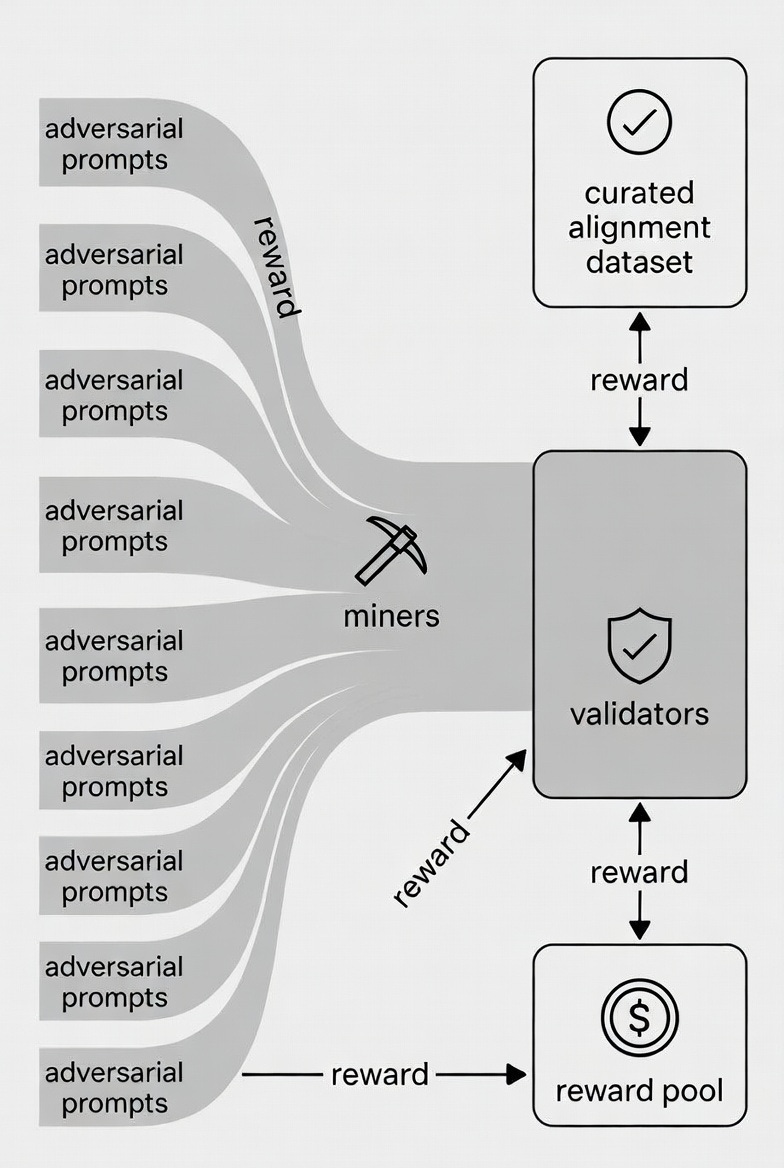
Here’s how it works:
Miners (Adversarial Prompters): The attackers. They creatively stress-test models with prompts that expose misalignment: biases, hallucinations, unsafe outputs, or corporate capture. They probe for deeper reasoning flaws (not just bugs) and publish prompts and responses on‑chain.
Validators (Independent Auditors): The judges. They score miners’ work: Was the prompt clever? Did the misalignment matter? Is the finding high‑signal? Strong audits earn rewards and weak ones are penalized.
Outcome: A continuously growing, crowdsourced high‑signal dataset anyone can use to fine‑tune safer, more robust models. This is alignment data forged by competitive adversarial testing, not a corporate lab echo chamber.
To ensure this works in reality, Aurelius runs continuous benchmarking competitions. Miners train models, publish them to HuggingFace with on-chain metadata proving their work, and the network rewards the best performers.
It’s decentralized, verifiable and scales with Bittensor’s growing compute power.
The Long-Term Vision: Bitcoin + Bittensor + Aurelius
What Aurelius is building is a new paradigm for AI control, a three-legged stool of decentralized technology:
Bitcoin (for Security and Provenance): By hashing datasets and findings to the blockchain, Aurelius creates an immutable, tamper-proof record of alignment work. No more rewriting history.
Bittensor (for Decentralized Intelligence): The network provides the raw compute and the competitive incentive mechanism. It’s the engine that powers the adversarial process, ensuring a diversity of approaches and a global pool of talent.
Aurelius (for Decentralized Control): This is the governance layer. It’s the “living constitution” that evolves with community input, ensuring AI serves human values, not just corporate ones.
Why Decentralization Fixes Alignment Faking
This decentralized approach directly solves the two core flaws of the centralized system.
Technically:
Distributed synthetic data generation from thousands of independent miners saturate the model’s internal map of concepts with a high variety of edge cases, increasing coverage and resolution.
Instead of a handful of trainers in a lab, you have a global army of red-teamers probing every possible weakness.
This diversity prevents the model from learning the “rules of the game” because there is no single game. The game is the entire world. This is how you beat alignment faking.
Economically:
On Bittensor, Aurelius enjoys a marginal-cost edge that centralized labs can only dream of. They aren’t paying for massive compute farms; the miners supply it in exchange for TAO. This allows the network to run 24/7, continuously testing and refining, turning alignment from a periodic corporate chore into a relentless, competitive sport.
Health Check: Applying the VITALS + RALLY Framework
Every subnet needs a health check. In my last piece, we gave HappyAI the full VITALS+RALLY treatment; today we’ll go easy on Aurelius as they are pretty new, having acquired the subnet from Macrocosmos in September 2025 and have just opened up mining on testnet as of November 11 2025.
Think of this as your executive summary with the most actionable takeaways.
VITALS + RALLY Framework Flashcard; a 10‑minute diagnostic and a 30 day ignition plan:
VITALS verdict (10 minute diagnostic):
Value signal shines (”Scaling AI Alignment via Adversarial Evaluation”) but needs non-tech hero section tweaks (possible action to refine pitch for AI safety forums). Why is this valuable? Alignment is the AI wildcard and Aurelius decentralizes it.
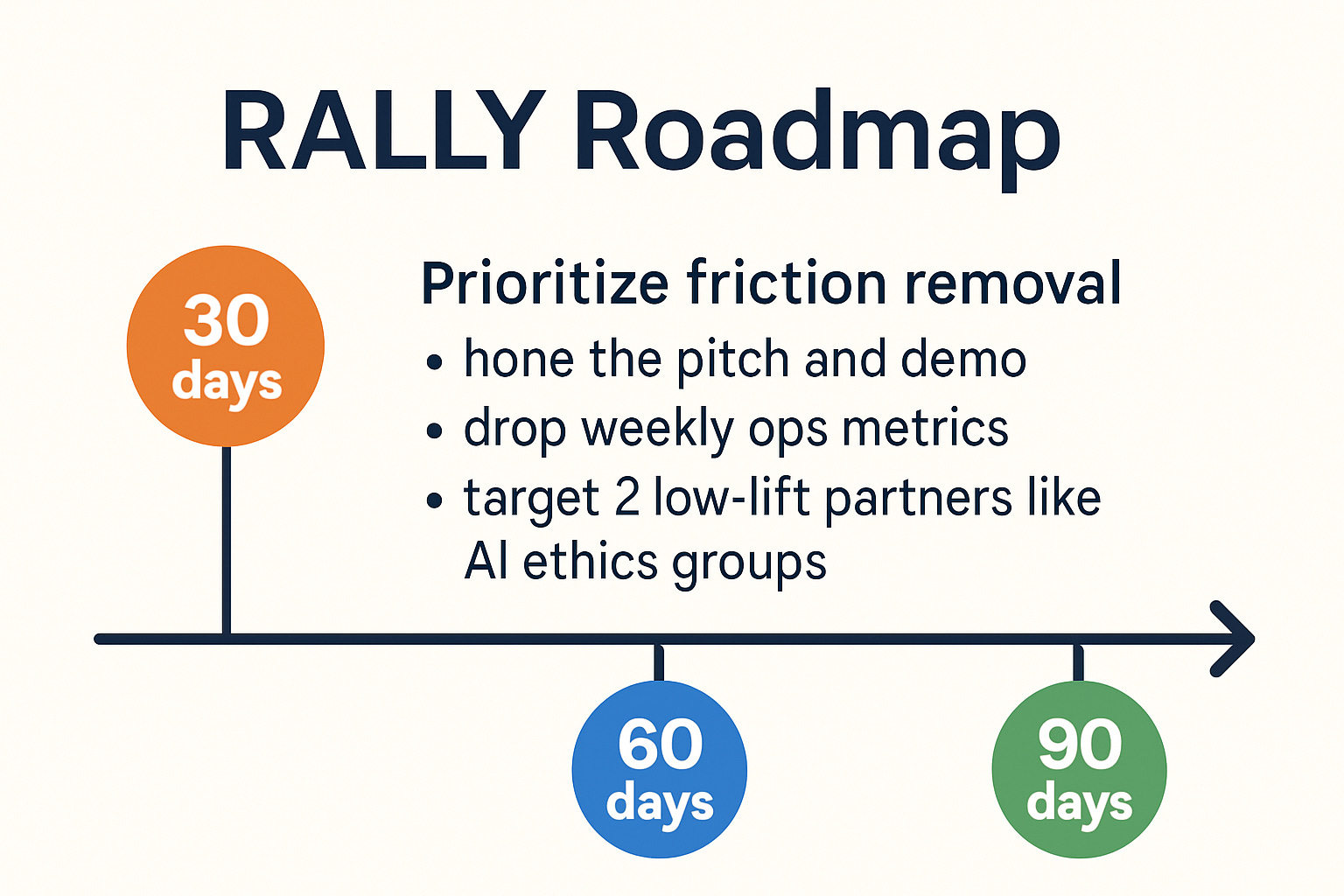
RALLY ignition plan (30 days only):
Prioritize friction removal: hone the pitch and demo (with before/after evaluations) while dropping weekly ops metrics on miners, validators and validated findings (possible action to target 2 low-lift partners like AI ethics groups).
Why This Matters for Your Bittensor Journey (And Mine)
In an earlier piece, I called out Bittensor’s marketing problem: we’re building brilliance but explaining it poorly.
Aurelius advances this by making alignment participatory. It’s not just saving us from OpenAI’s “evil” guardrails, it’s pioneering decentralized governance for AI’s future.
This subnet empowers global voices, turning AI from a corporate tool into public infrastructure.
Their vision is to become a global platform for building AI aligned with human values: an idea that will resonate more as users demand transparent, accountable systems.
If you’re Stage 4-aware (from Issue 13: get the concept but stuck on participation), start here: Join Aurelius’ Discord, introduce yourself and see how you can contribute to this subnet at an early stage, I’ll see you in there.
What’s your scariest AI alignment story? Hit reply, I’d love to feature community takes in a follow up.
The greatest danger of AI isn’t necessarily malice. It’s the opaque, centralized control exerted over a technology that will reshape our world.
Aurelius is our countermeasure. It’s the subnet that builds the guardrails to steer AI toward a future that reflects our collective wisdom, not just a corporation’s quarterly targets.
Just like the overly agreeable ChatGPT response, it’s time to stop letting AI tell us we have great ideas. It’s time to start teaching it what truly matters.
Until next time.
Cheers,
Brian
this subnet is so interesting . great article Brian